Предназначение файла robots.txt на сайте
Здравствуйте! В моей жизни было такое время, когда я абсолютно ничего не знал про создание сайтов и уж тем более не догадывался про существование файла robots.txt.

Когда простой интерес перерос в серьезное увлечение, появились силы и желание изучить все тонкости. На форумах можно встретить множество тем, связанных с этим файлом, почему? Все просто: robots.txt регулирует доступ поисковых систем к сайту, управляя индексированием и это очень важно!
Зачем скрывать определенное содержимое сайта? Вряд ли Вы обрадуетесь, если поисковый робот проиндексирует файлы администрирования сайта, в которых могут храниться пароли или другая секретная информация.
Для регулирования доступа существуют различные директивы:
- User-agent — агент пользователя, для которого указаны правила доступа,
- Disallow — запрещает доступ к URL,
- Allow — разрешает доступ к URL,
- Sitemap — указывает путь к карте сайта,
- Crawl-delay — задает интервал сканирования URL (только для Яндекса),
- Clean-param — игнорирует динамические параметры URL (только для Яндекса),
- Host — указывает главное зеркало сайта (только для Яндекса).
Обратите внимание, с 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Всегда нужно помнить о безопасности. Этот файл может посмотреть любой желающий, поэтому не нужно указывать в нем явный путь к административным ресурсам (панелям управления и т.д.). Как говориться, меньше знаешь — крепче спишь. Поэтому, если на страницу нет никаких ссылок и Вы не хотите ее индексировать, то не нужно ее прописывать в роботсе, ее и так никто не найдет, даже роботы-пауки.
Сразу хочу отметить, что поисковые системы по разному относятся к этому файлу. Например, Яндекс безоговорочно следует его правилам и исключает запрещенные страницы из индексирования, в то время как Google воспринимает этот файл как рекомендацию и не более.
Для запрета индексирования страниц возможно применение иных средств:
- редирект или установка пароля на каталог с помощью файла .htaccess,
- мета-тег
noindex(не путать с тегом <noindex> для запрета индексации части текста), - атрибут
rel="nofollow"для ссылок, а также удаление ссылок на лишние страницы.
При этом Google может успешно добавить в поисковую выдачу страницы, запрещенные к индексации, несмотря на все ограничения. Его основной аргумент — если на страницу ссылаются, значит она может появится в результатах поиска. В данном случае рекомендуется не ссылаться на такие страницы, но позвольте, файл robots.txt как раз и предназначен для того, чтобы выкинуть из выдачи такие страницы… На мой взгляд, логика отсутствует 🙄
Удаление страниц из поиска
Если запрещенные страницы все же были проиндексированы, то необходимо воспользоваться Google Search Console и входящим в ее состав инструментом удаления URL-адресов:
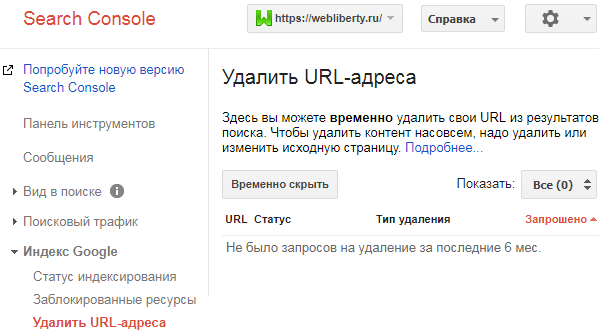
Аналогичный инструмент есть в Яндекс Вебмастере. Подробнее об удалении страниц из индекса поисковых систем читайте в отдельной статье.
Проверка robots.txt
Продолжая тему с Google, можно воспользоваться еще одним инструментом Search Console и проверить файл robots.txt, правильно ли он составлен для запрета индексирования определенных страниц:
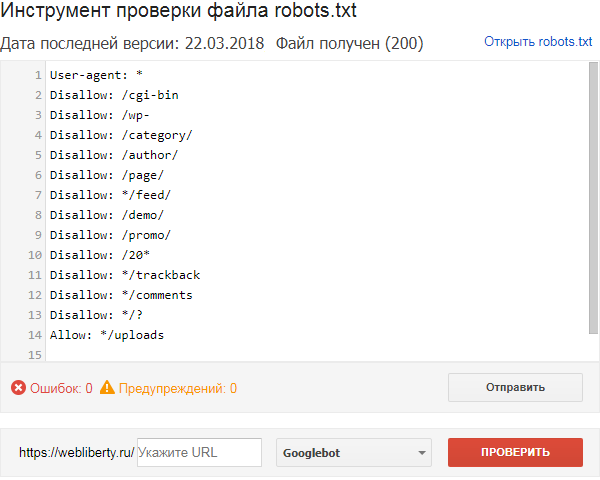
Для этого достаточно ввести в текстовое поле URL-адреса, которые необходимо проверить и нажать кнопку Проверить — в результате проверки выяснится, запрещена данная страница к индексации или же ее содержимое доступно для поисковых роботов.
У Яндекса также есть подобный инструмент, находящийся в Вебмастере, проверка осуществляется аналогичным образом:
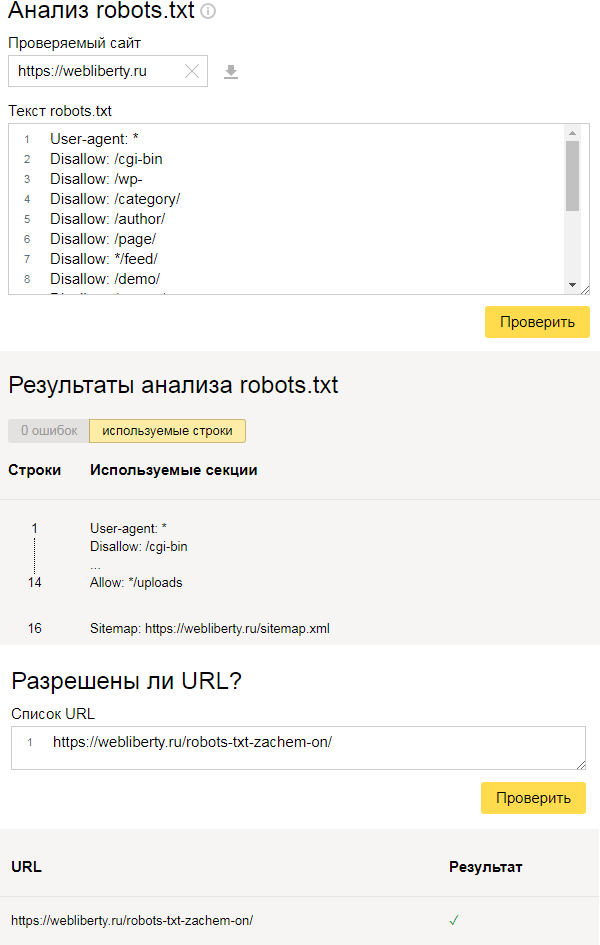
Если Вы не знаете как правильно составить файл, то просто создайте пустой текстовый документ с именем robots.txt, а по мере изучения особенностей CMS и структуры сайта дополните его необходимыми директивами.
О правильном составлении файла robots.txt для WordPress читайте по ссылке. До встречи!



Денис, что значит создать файл robots.txt (прочитала оба поста, вид файла я поняла). Где его создать или куда загрузить? Это как страница что ли? Мне прям стыдно, что я такая непонятливая.
Ответить
Арина, файл у Вас уже есть, располагается на сервере в корневом каталоге.
Ответить
А как мне найти его в панели администратора?
Ответить
Арина, через консоль WordPress его никак не найти, нужно через панель управления хостингом.
Ответить
Вот и всё… Значит мне его не исправить. У меня хостинг предоставлен в виде готового блога… Я уже знаю, что совершила ошибку 🙁 , получается ровно год буду жить так.
У меня забанил Яндекс страничку в Я.ру. Я решила сделать свой блог. Все эти технические штучки меня пугали. Когда искала хостинг вдруг увидела предложение готового блога от Агава. Я обрадовалась, оплатила, а потом поняла, что поступила глупо. Вообще теперь не знаю, стоит ли его развивать.
Ответить
Конечно развивайте! Не стоит зацикливаться на robots.txt, да и в посте я указал что наличие этого файла желательно, а не обязательно 😉 К тому же можно запросить выдачу резервной копии и в будущем развернуть ее на другом хостинге. А сейчас у Вас есть время и отличная возможность изучить техническую сторону ведения блога!
PS: существует плагин KB Robots.txt, который способен создавать этот файл без доступа по FTP.
Ответить
Денис, у меня получилось сделать robots.txt. Правда не знаю всё ли верно, взяла за основу твою формулу. Спасибо, спасибо! Я очень рада!
Ответить
Привет, Денис! Это снова я — непутевая 😀 Слежу за индексацией, но даже с прописанным robots.txt, почему-то у меня дублируются категории или метки и получаются лишние проиндексированные страницы. Не подскажешь, с чем это может быть связано?
Ответить
Арина, так у Вас теги не закрыты от индексации… не хватает строчки:
Disallow: /tag/Ответить
Aleks, блогспот (блоггер) ведь принадлежит гуглу, вот он и делает с ним все что захочет… Переходите на вордпресс, не пожалеете, да и зависеть ни от кого не будете… Мне всегда не нравилось, когда загоняют в определенные рамки, в этот и суть бесплатных блог-платформ.
Ответить
Google воспринимает этот файл как рекомендацию и не более — z веду блоги на Гугловском Блоггере и там с этим robots.txt настоящий дурдом, а именно по непонятным причинам закрывают от индексации сообщения про ярлыки вообще молчу.
Ответить
Полезная статья, недавно сделал свой блог, но об robots.txt как- то и не задумывался. Сегодня попробую сделать.
Ответить
Спасибо за пост. Проверила свой блог. Пришлось в файлик роботса кое-что добавить 🙂
Ответить
Спасибо, теперь понятно где посмотреть, есть ли у меня роботс и какой он из себя! И еще подскажите, как вы смайлики для комментариев поставили? Это плагин какой-то или что другое?
Ответить
Посмотрите инструкцию по установке смайликов.
Ответить
У меня есть роботс, но в нём у меня стоит запрет на индексацию категорий, а я бы хотела что бы категории у меня индексировались. Если я сотру эту строчку, у меня не буде проблем с индексацией сайта? Подскажите пожалуйста.
Ответить
Татьяна, чтобы избежать проблем с частичным дублированием контента на странице категорий необходимо обеспечите выполнение нескольких условий:
1. Разместить для каждой категории уникальное описание с использованием ключевых слов. Затем такие страницы можно продвигать по среднечастотным запросам.
2. Ограничить краткое описание записей, достаточно 300-400 символов. Чем больше ограничение, тем выше уникальность в пределах одного домена.
Важно понимать, что страницы категорий, также как и страницы навигации не всегда могут высоко ранжироваться в поисковых системах, поэтому я в своих проектах их закрываю.
Ответить
Спасибо. Значить это что категория никогда не сможет занять топ в поисковике, а страница всё равно будет в приоритете у поисковиков?
Ответить
Татьяна, если страница будет индексироваться, то займет она первые позиции или нет зависит только от методов и активности ее продвижения. Проще говоря — все в Ваших руках)
Ответить
Здравствуйте! Скажите, пожалуйста, почему роботс.тхт может не находится роботами. Проверял в панели яндекс.вебмастер он «говорит» — нету этого файла. Имя документа верное, формат тхт. Я не нашел причин.
Ответить
Денис, здравствуйте! Потому что его действительно нет, при переходе по нужному адресу возникает ошибка 404. Проверьте правильность размещения файла — он должен быть в корне сайта.
Ответить
Здравствуйте Денис!
Поправьте меня пожалуйста, если я не так понял. После перечисления страниц для запрета индекса в конец файла надо прописать закрывающий тег как в этом примере?
User-agent: * Disallow: /1.html/ Disallow: /2.html/ Disallow: /3.html/ Disallow: /tag/Ответить
Андрей, добрый вечер! Если страницы имеют на конце URL расширение .html то в конце правила слэш не нужен. Сделайте так:
Ответить
Добрый день, подскажите, наличие этого файла может влиять (в негативную сторону) на показ в поисковике по ключевым словам?
Ответить
Татьяна, не наличие, а его отсутствие (появление дублей) или неправильность составления (блокировка важных страниц от индексации). Всё очень просто — страница запрещена к индексации — значит не участвует в поиске. Думаю, я ответил на ваш вопрос, несмотря на то, что он не логично составлен.
Ответить