4 небанальные директивы Meta Robots и как их использовать
Meta Robots — это метатег, который позволяет настроить инструкции по индексации сайта. Его плюсы заключаются в надёжности и простоте установки. Но многие вебмастера и SEO-специалисты зачастую ограничиваются лишь директивами noindex и nofollow, указывающими на запрет индексации страниц сайта и содержащихся на них ссылок.
Я решил подробнее ознакомиться с возможностями Meta Robots, а потому в рамках данной статьи разберу и другие способы использования Meta Robots, которые вы сможете применить для SEO-продвижения вашего сайта.
Директивы Meta Robots и какие поисковые системы их учитывают
Всего существует чуть больше десятка основных директив Meta Robots, которые можно комбинировать между собой:
noindex— запрещает индексирование страницы.nofollow— запрещает роботу переходить по ссылкам с этой страницы.none— аналогичен комбинации noindex, nofollow.all— нет ограничений на индексирование и показ контента. Директива используется по умолчанию и не влияет на работу поисковых роботов, если нет других указаний.noimageindex— не индексировать изображения на этой странице.noarchive— запрещает показывать ссылку «Сохраненная копия» для определенной страницы.nocache— указывает на необходимость отправить запрос на сервер для валидации ресурса перед использованием кэшированных данных.nosnippet— запрещает показывать видео или фрагмент текста в результатах поиска.notranslate— запрещает предлагать перевод этой страницы в результатах поиска.unavailable_after: [RFC-850 date/time]— указывает точную дату и время, когда нужно прекратить сканирование и индексирование этой страницы.noodp— не использовать метаданные из проекта Open Directory для заголовков или фрагментов этой страницы.noydir— не брать название сайта и его описание из Yahoo! Directory (каталога Yahoo!).noyaca— не использовать описание из Яндекс.Каталога для сниппета в результатах поиска.
Некоторые из директив по-разному воспринимаются роботами тех или иных поисковых систем. В таблице ниже собрана информация о том, как боты систем Google, Yahoo, Bing и Яндекс работают с директивами Meta Robots.
| Директивы | Yahoo | Bing | Яндекс | |
|---|---|---|---|---|
| index | Да* | Да* | Да* | Да |
| noindex | Да | Да | Да | Да |
| follow | Да* | Да* | Да* | Да |
| nofollow | Да | Да | Да | Да |
| none | Да | ? | ? | Да |
| all | Да | ? | ? | Да |
| noimageindex | Да | Нет | Нет | Нет |
| noarchive | Да | Да | Да | Да |
| nocache | Нет | Нет | Да | Нет |
| nosnippet | Да | Нет | Да | Нет |
| notranslate | Да | Нет | Нет | Нет |
| unavailable_after | Да | Нет | Нет | Нет |
| noodp | Нет | Да** | Да** | Нет |
| noydir | Нет | Да** | Нет | Нет |
| noyaca | Нет | Нет | Нет | Да |
* Поисковая система не имеет официальной документации, которая бы подтверждала поддержку этой директивы. Но предполагается, что поддержка исключающего значения (например, nofollow) подразумевает поддержку положительного (например, follow).
** Теги noodp и noydir перестали поддерживаться, и, вероятно, не работают.
Директивы Meta Robots, которые стоит использовать в SEO
Как мы видим из предыдущей таблицы, не все атрибуты метатега Robots поддерживаются поисковой системой Google, под которую оптимизируют сайты большинство разработчиков и SEO-специалистов. Поэтому рассмотрим те атрибуты метатега Robots, которые поддерживаются Google:
- nosnippet,
- noimageindex,
- noarchive,
- unavailable_after.
Все они прописываются в блоке <head> страницы, к которой вы хотите применить те или иные инструкции по индексации.
Nosnippet
Эта директива может понадобиться, если, например, вы хотите предотвратить попадание контента вашего сайта в блоки с готовыми ответами Google (Featured Snippet). Несмотря на то, что фрагмент контента в Featured Snippet, как правило, позволяет повысить конверсию, всё же он может отвлекать внимание от самого сайта. То есть, у пользователей, получивших ответ на свой вопрос, пропадает надобность кликать по ссылке.
Для решения проблемы вам следует использовать инструкцию следующего вида:
<meta name="robots" content="nosnippet">Также важно учитывать, что атрибут nosnippet отключает и отображение расширенных сниппетов в результатах поиска.
К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов. Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц.
Noimageindex
Директива noimageindex позволит скрыть графический контент на вашем сайте из результатов поиска по картинкам. Это может быть полезно, если вы, к примеру, хотите разместить на своём блоге уникальные изображения и при этом минимизировать риск воровства.
Чтобы запретить поисковым системам индексировать изображения, задайте в блоке <head> html-документа следующую директиву:
<meta name = "robots" content = "noimageindex">Действие необходимо повторить с каждой страницей, которая содержит изображения, которые вы хотите скрыть от поисковиков. Учитывайте, что если другие сайты уже ссылались на ваши изображения, поисковики могут продолжать индексировать их.
Запрещая индексацию изображений, не забывайте о том, что поиск по картинкам может приносить хороший дополнительный трафик вашему сайту.
Noarchive
Директива может пригодиться тем, кто работает с интернет-магазинами. К примеру, на вашем сайте есть страницы с товарами и указанной на них стоимостью. Так как цены с определённой периодичностью меняются, кэшированные страницы товаров могут быстро терять свою актуальность. Для предотвращения кэширования поместите в <head> страницы такую строку:
<meta name="robots" content="noarchive">Вопреки распространённому мнению, директива noarchive никак не влияет на ранжирование — эту информацию подтвердил в своем Твиттере ведущий аналитик компании Google, специалист отдела качества поиска по работе с вебмастерами Джон Мюллер (John Mueller).
Unavailable_after
Директива unavailable_after наиболее актуальна для страниц с акционными предложениями. Так как по истечению времени действия акции они теряют свою актуальность, вы можете указать поисковикам дату крайнего срока индексации контента. Дату и время нужно указывать в формате RFC 850.
К примеру, если вам нужно исключить возможность индексации страницы после 25 марта 2019 года, используйте метатег следующего вида:
<meta name="googlebot" content="unavailable_after: 25-Mar-2019 00:00:00 EST">Отдельно отметим, что для правильного функционирования тега необходимо, чтобы он был прописан до первого обхода роботом. В таком случае запрос на удаление из поисковой выдачи займёт примерно сутки после указанной даты.
Проверка правильности Meta Robots и его содержимого в Netpeak Spider
Перед проверкой атрибутов Meta Robots важно узнать, какие страницы индексируются на сайте, иначе не будет смысла внедрять вышеописанные атрибуты. Скачать Netpeak Spider можно на официальном сайте.
Программа доступна для операционных систем Microsoft Windows и Mac OS, поддержка платформы Linux в данный момент не доступна, но находится в разработке. Вы можете пользоваться бесплатной версией в течение 14 дней без каких либо ограничений.
c6c39672 при оформлении заказа и получите специальную скидку 10% на покупку Netpeak Spider и Netpeak Checker!С помощью Netpeak Spider вы можете найти запрещённые к индексации страницы. На таких страницах программа делает особый акцент, отмечая ошибками:
- Заблокировано в Meta Robots. Показывает страницы, запрещённые к индексации с помощью инструкции
<meta name="robots" content="noindex">в блоке<head>. - Nofollow в Meta Robots. Показывает страницы, содержащие инструкции
<meta name="robots" content="nofollow">в блоке<head>.
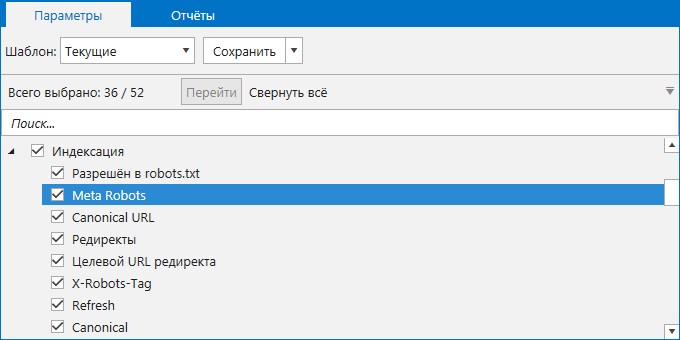
Для проверки сайта откройте программу и перейдите на вкладку «Параметры» на боковой панели. Найдите раздел «Индексация» и проверьте, отмечен ли галочкой пункт «Meta Robots». Если пункт не будет отмечен, программа не проанализирует метатег, и вы в финальном отчёте не увидите данных о нём.
Для сканирования всего сайта введите его начальный URL в адресную строку и нажмите кнопку «Старт». Если вам необходимо просканировать список страниц, зайдите в меню «Список URL» и выберите удобный вам способ добавления URL (ввести вручную, загрузить из файла или Sitemap, вставить из буфера обмена), после чего запустите сканирование.

По завершению сканирования получить информацию о Meta Robots вы можете несколькими путями:
1. В основной таблице на вкладке «Все результаты». В столбце Meta Robots просмотрите директивы, которые содержатся в соответствующем теге каждой из просканированных страниц.
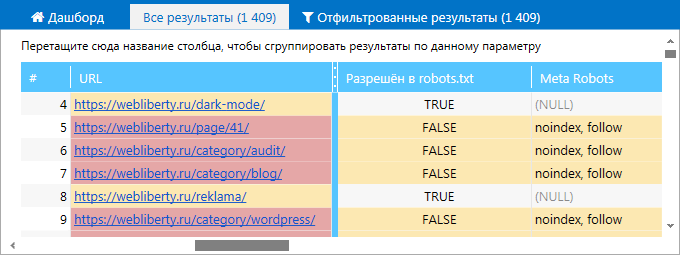
2. На вкладке «Ошибки» боковой панели. Найдите ошибки, связанные с Meta Robots, и кликните по их названию. В таблице отфильтрованных результатов вы увидите полный список страниц, на которых были найдены эти ошибки.
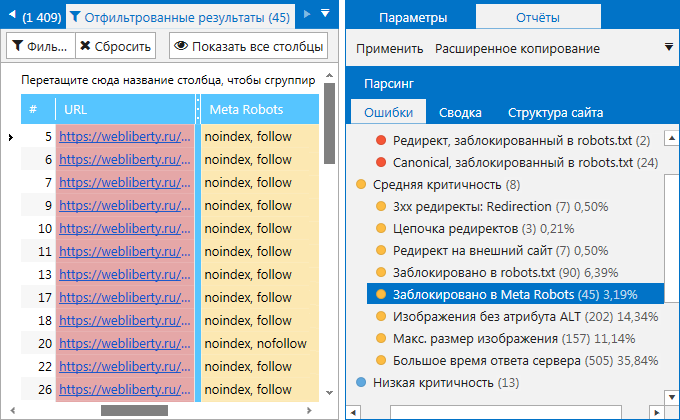
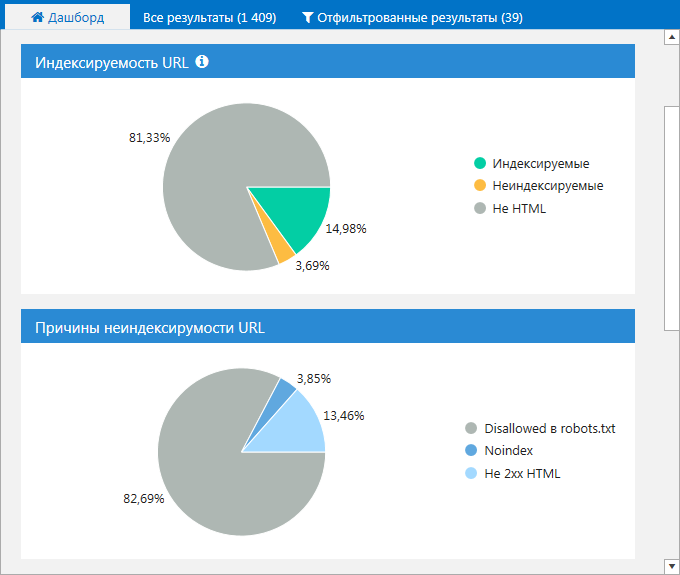
3. На вкладке «Дашборд». Вы можете просмотреть данные в виде диаграмм об индексируемых страницах на сайте, а также узнать причины их неиндексируемости. Кликните на интересующую вас область, чтобы получить список страниц, соответствующих тому или иному значению.
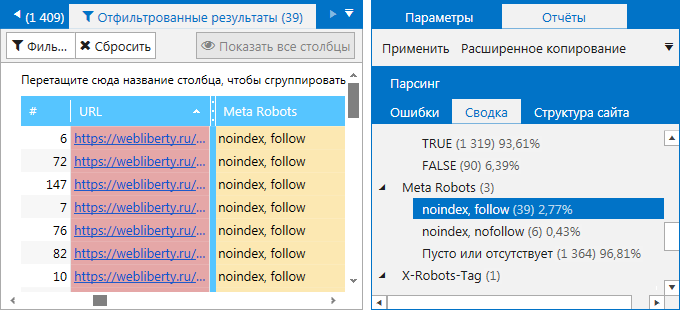
4. На вкладке «Сводка» на боковой панели. Здесь вы можете ознакомиться как закрытыми от индексации страницами, так и посмотреть, какие ещё значения помимо noindex, nofollow заданы в метатеге Robots. Найдите пункт «Meta Robots» со списком всех имеющихся на сайте директив. Кликните на любую из них, чтобы ознакомиться со страницами, на которых они были найдены.
При необходимости вы можете воспользоваться функцией «Экспорт», чтобы выгрузить отфильтрованные результаты в отдельный файл формата .xlsx на свой компьютер. Нажмите на кнопку «Экспорт» в левом верхнем углу над результатами сканирования или выберите в соответствующем меню команду «Результаты в текущей таблице».
Коротко о главном
Meta Robots — удобный инструмент, который позволяет управлять инструкциями по индексации сайта и его отдельных страниц. Однако зачастую его использование ограничивается атрибутами запрета индексации — noindex, nofollow.
На деле же он может использоваться как минимум с 4 директивами, которые полноценно воспринимаются поисковыми роботами Google и помогают решить разного рода SEO-задачи. В их числе — nosnippet, noimageindex, noarchive и unavailable_after.

Проверить директивы метатега Robots всего сайта или списка определённых URL удобнее всего с помощью Netpeak Spider. Программа покажет все возможные ошибки, связанные с метатегами, и предоставит данные об атрибутах в максимально наглядном виде.
Краулер программы выполняет глубокий анализ сайта в автоматическом режиме, получает полную его структуру и находит ошибки технической оптимизации. Умеет находить битые ссылки и редиректы, обнаруживать дублирование страниц, Title, Description, заголовков H1 и т.д — проверяет более 50 ключевых параметров. Настоятельно рекомендую!



Директивы эти действительно нужны, но они все равно служат вроде как рекомендацией. Часто вижу в вебмастере гугла — страница проиндексирована, несмотря на запрет в роботс и тому подобное.
Ответить
Огромное Вам спасибо за Ваш блог! Уйма полезной информации и настолько в развернутом виде, что всё сразу ясно и понятно. Своеобразная мини школа для меня. Спасибо за ваш труд!
Ответить
Иван, директивы Meta Robots и файла robots.txt для поисковой системы Google действительно являются лишь рекомендацией, о чём открыто говорится в справочной информации. Его логика такая: если на страницу ссылаются, значит она может быть полезна и проиндексирована.
Яндекс, по моим наблюдениям, строго следует указаниям директив и соблюдает правила индексирования.
Ответить
Когда на курсах проходили индексацию, нам рекомендовали тоже ставить
nofollow, хотя по идее сейчас уже структура интернета другая, должны вступить в силу изменения по поисковикам.Ответить